# <center>文字雲--108謝沛寰</center>
###### tags : `MCL` `108-2 prject`
## 靜態網頁v.s.動態網頁
> 1.靜態網頁:即HTML。是網站建置的基礎技術,常和CSS、Javascript配合,寫成一個適合觀看的網頁。一般的判斷方式是:網頁副檔名為htm或html,就是靜態網頁。靜態網頁比起動態網頁更容易被瀏覽器所接受,因此,很多動態網頁會將動態網頁轉變成靜態網頁,形成「偽靜態網頁」。這麼做可以提高搜尋引擎對其的友善度,達到排名優化的成效。
> 2.動態網頁:動態網頁主要是搭配伺服器和資料庫在運作的,是指可以跟網頁做互動編譯的網頁,例如:購物車、會員功能等等。動態網頁的內容會因為使用者輸入不同的資料,而有不同的編譯方式,從而使動態網頁的內容有所改變。
:::info
但簡單來說,動態和靜態網頁最大的差別就在於 **有沒有javascript的協助從資料庫導入資料**
:::
### 那麼,怎麼分辨動態網頁和靜態網頁呢?
一般來說,動動你的手指按下鍵盤上的 `F12` 並檢查**開發者工具**,如果出程式碼出現了`<script><\script>` 那就**有可能**是動態網站。
但更能確定的方法就是直接利用python的`request`套件庫,直接對目標網站爬蟲。如果是靜態網站,就可以直接得到我們要的東西,但如果是動態網站,則不會得到回傳的東西。
這時候就要改用python的`selenium`套件庫來進行爬蟲。
## 文字雲
這次爬取的網頁是[這個](https://technews.tw/category/internet-of-things-internet/)
:::spoiler 程式碼
```python=
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup as bs
import requests
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from PIL import Image
import numpy as np
jieba.load_userdict('dict.txt')
hash = {} #創建一個字典
for t in range (1,15) : #爬取1-15頁的資料
url = 'https://technews.tw/category/internet-of-things-internet/page/'+str(t)
r = requests.get(url)
response = r.text
soup = bs(response,'lxml')
href = soup.find_all('a',rel = 'bookmark') #找到頁內超連結
#取出內文
for k in href :
t1 = k.get('href')
t1 = 'https:' + t1 if t1[0] == '/' else t1
r = requests.get(t1)
soup = bs(r.text,'lxml')
content = soup.select('.indent>p')
#將內文轉成文字
article = []
for c in content:
article.append(c.text)
articleAll = '\n'.join(article) #每行合併,即獲得所有要爬取的文字
#設定高頻率出現的詞,之後進行過濾
stopwords = {}.fromkeys(["也","但","來","個","再","的","和","是","有",'於','為','都','而','能',':','《','》',"更","會","可能","有何","從","對","與","等","、","了","就", '卻','不過','時','\n','越','為','這種','多','越來','在','你','我','他','說',' ',',','。','(',')','!','?'])
Sentence = jieba.cut_for_search(articleAll)
# 計算stopwords之外的詞頻
for item in Sentence:
if item in stopwords:
continue
elif item in hash:
hash[item] += 1
else:
hash[item] = 1
font = "C:\\Windows\\Fonts\\AdobeFanHeitiStd-Bold.otf"
wc = WordCloud(font_path = font, #設定字型
background_color="white", #背景顏色
max_words = 2000 , #文字雲顯示最大詞數
stopwords=stopwords) #停用字詞
wc.generate_from_frequencies(hash)
#印出結果
plt.imshow(wc)
plt.axis("off")
plt.figure(figsize=(20,10), dpi =200)
plt.show()
wc.to_file('wordcloud.jpg') #以.jpg輸出
```
:::
:::spoiler 斷詞方式
* 全模式
* 精確模式
* 搜尋引擎模式
:::
:::spoiler 成品

:::
:::spoiler 遇到的問題
* 斷詞不夠精確
* 出現很多方形框框
* 較難圖形化
:::
:::spoiler 各種失敗品



:::
## 資料整合
>文字雲是資料整合的典型應用
>[color=#CC00FF]
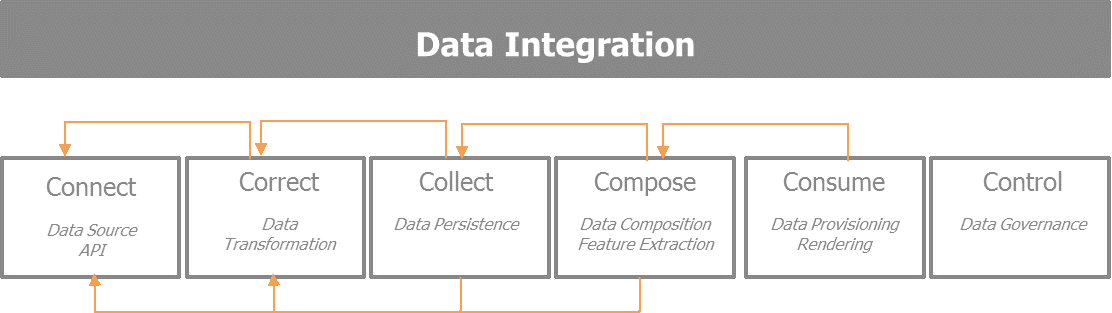
### 6C
| 6C | 核心 | 功用 | 應用 |
| ------- | ------------------------------------ | --------------------------------------------------------------------------------------------- | --------------------------------------------------------------- |
| Connect | data source API | 目標是從各種各樣資料來源選擇資料,資料來源會提供APIs,輸入格式,資料採集的速率,和提供者的限制。 | |
| Correct | data transformation | 聚焦於資料轉移以便於進一步處理,同時保證維護資料的質量和一致性。 | |
| Collect | data persistence | 資料儲存在哪,用什麼格式。 | |
| Compose | data composition feature extraaction | 集中關注如何對已採集的各種資料集的混搭。 | 利用jieba進行斷詞;利用nltk進行自然語言處理 |
| Consume | data composition rendering | 關注資料的使用、渲染以及如何使正確的資料在正確的時間達到正確的效果。 | 文字雲的輸出。 |
| Control | data governance | 資料的管控。 | 將多個輸出影像存入不同檔案目錄以便搜尋,此為初步的Control處理。 |
## API 的概念
{%youtube zvKadd9Cflc %}
Application Programming Interface;應用程式介面
### API的應用
* airbnb
* trivago
## 參考資料
* https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/632116/
* https://www.jamleecute.com/%E7%B6%B2%E8%B7%AF%E7%88%AC%E8%9F%B2-web-crawler-text-mining-python/
* https://kknews.cc/zh-tw/tech/p5xoaee.html
* https://www.piece2ec.com.tw/news.asp?id=1969&Class_ID=2
* https://medium.com/codingbar/api-%E5%88%B0%E5%BA%95%E6%98%AF%E4%BB%80%E9%BA%BC-%E7%94%A8%E7%99%BD%E8%A9%B1%E6%96%87%E5%B8%B6%E4%BD%A0%E8%AA%8D%E8%AD%98-95f65a9cfc33
* https://medium.com/pyladies-taiwan/nltk-%E5%88%9D%E5%AD%B8%E6%8C%87%E5%8D%97-%E4%B8%80-%E7%B0%A1%E5%96%AE%E6%98%93%E4%B8%8A%E6%89%8B%E7%9A%84%E8%87%AA%E7%84%B6%E8%AA%9E%E8%A8%80%E5%B7%A5%E5%85%B7%E7%AE%B1-%E6%8E%A2%E7%B4%A2%E7%AF%87-2010fd7c7540