# <center>資料科學</center>
###### tags: `MCL` `108-2-project`
> 以下內容很多不是我個人擁有的資料,希望各位參考即可不要流傳出去,保護著作權、智慧財產權,謝謝大家,祝大家學習愉快 👍加油 💪
[學習企劃書](https://hackmd.mcl.math.ncu.edu.tw/r_QcVi5-STefkhA3kYFNyw)
## 摘要
這次報告主要分四大部分介紹資料科學這個領域,著重在說明如何入門、必備知識以及此領域在行業中的角色。
ㄧ、介紹資料科學
二、資料科學的實作流程與方法
三、資料專題實做寫code
四、很大量相關知識的補充
## 資料科學領域
### 一、什麼是資料科學
首先所有資訊產業都
----

----
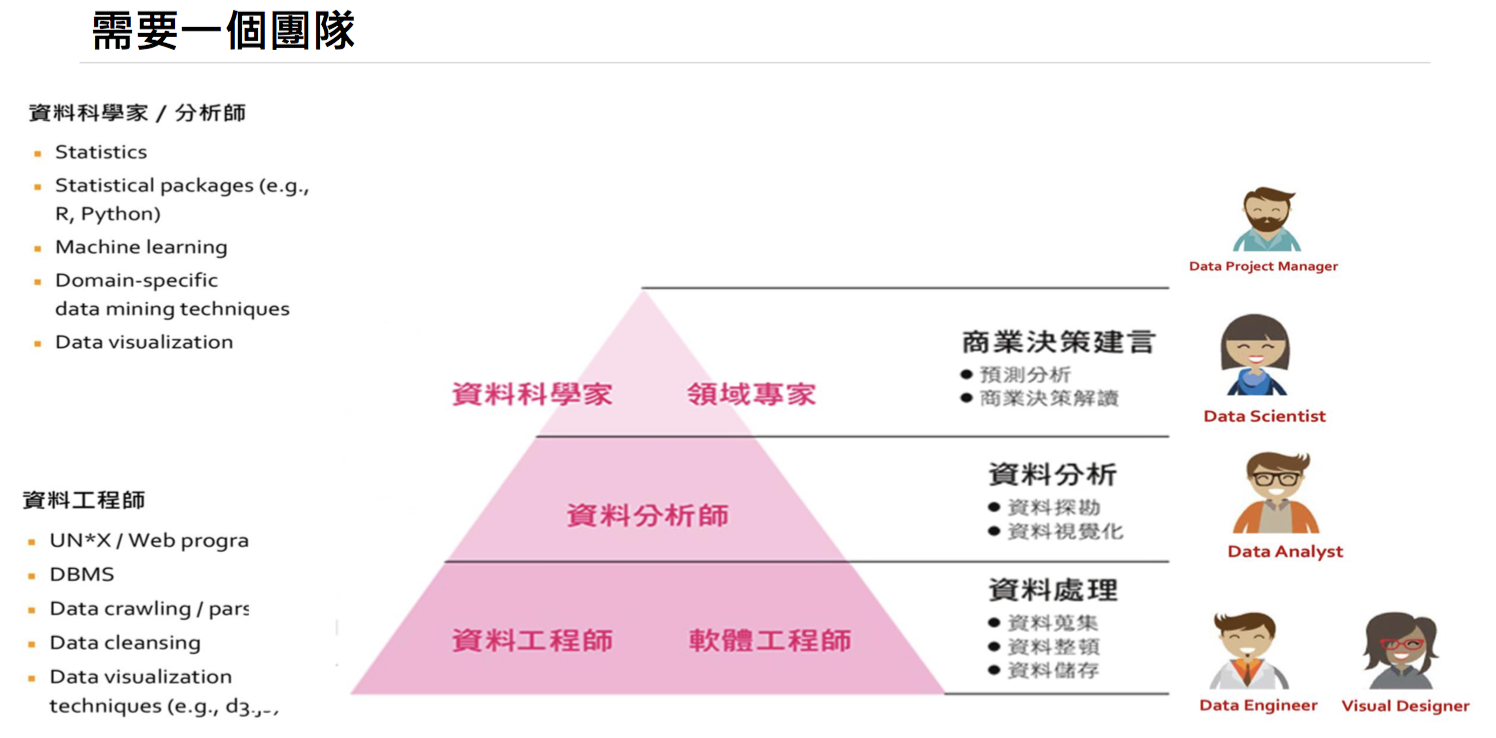
他分四種部份討論
----
----
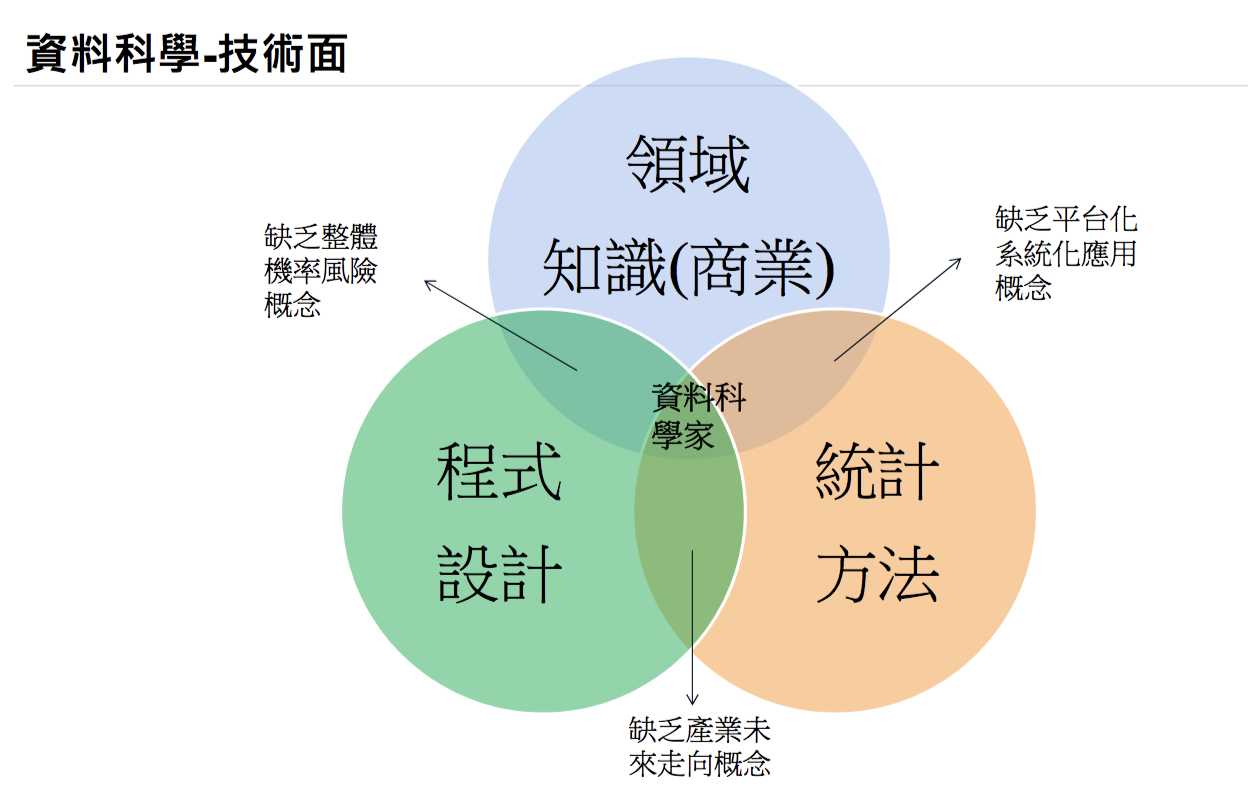
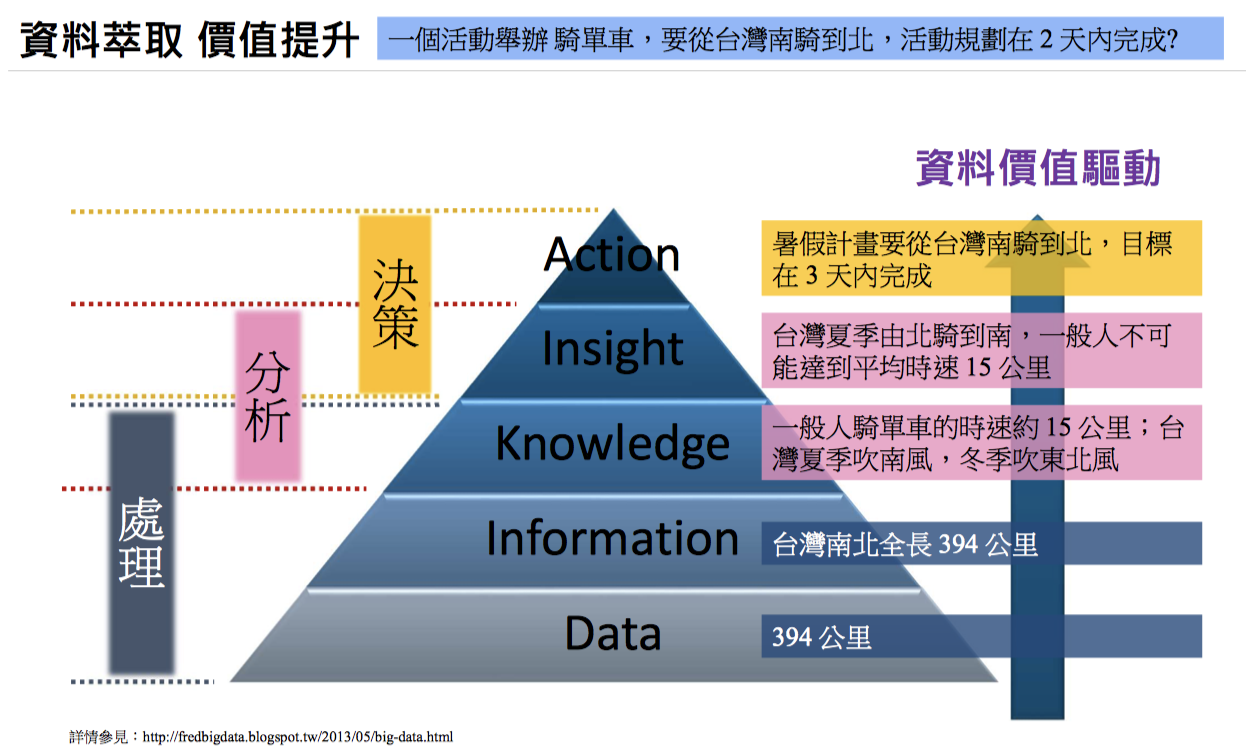
舉例來說
----
先了解跟區分很多很容易搞不清楚的領域

----
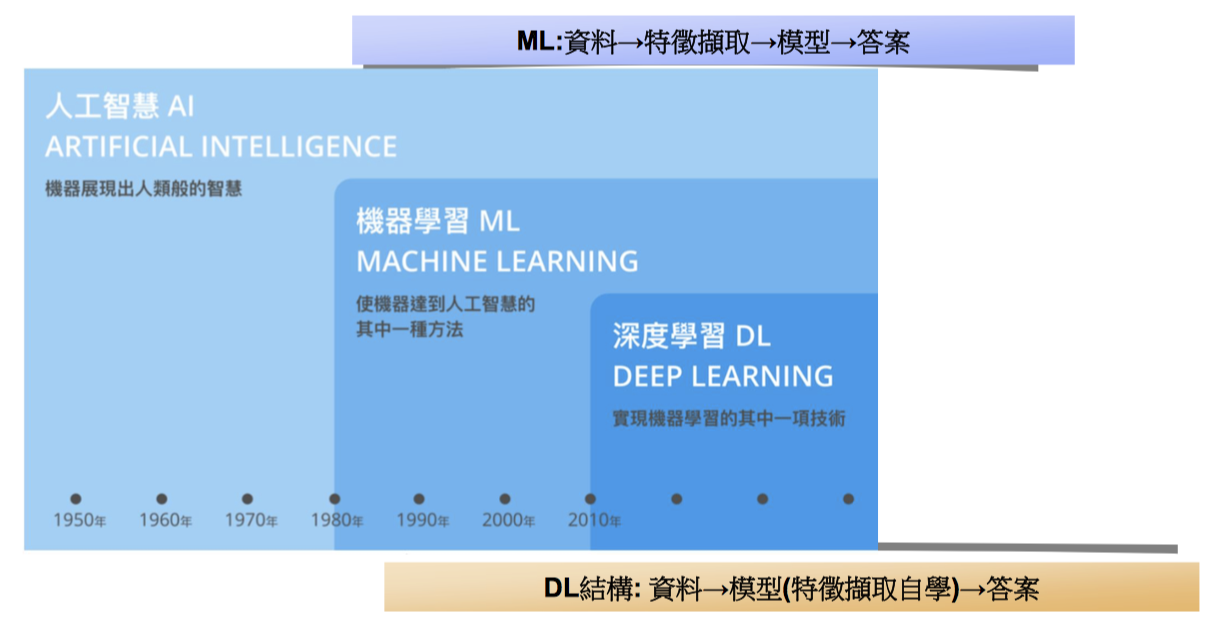
AI & ML & DL
----
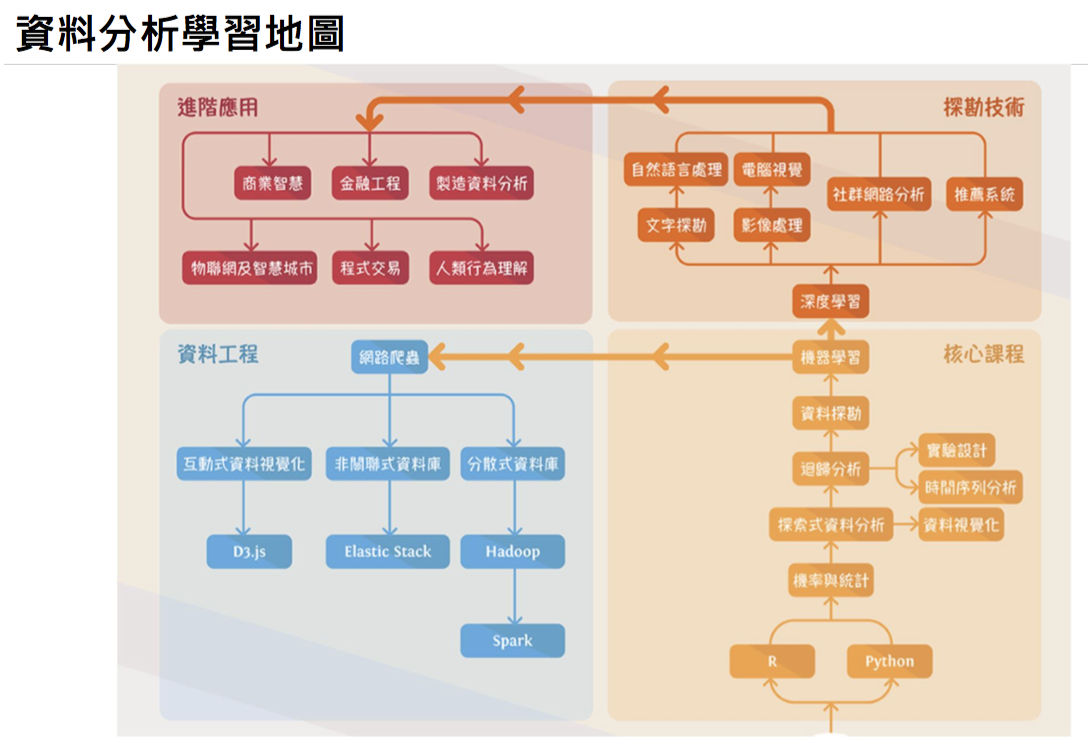
如何踏入這個領域
----
----
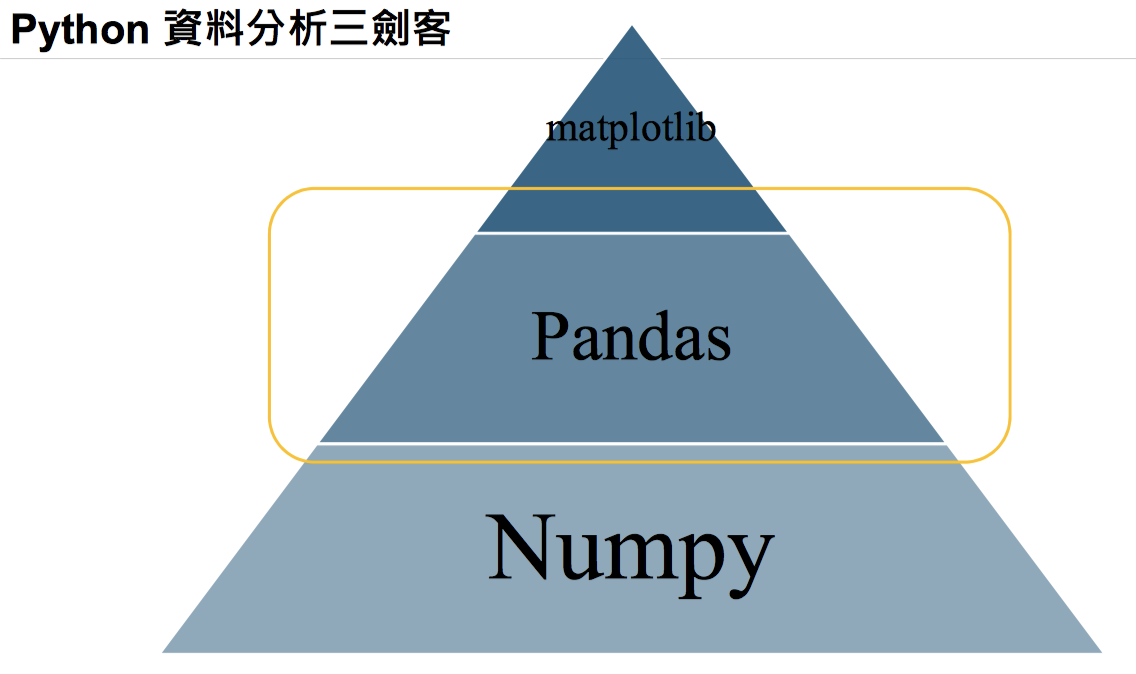
但是!到處都有 python 的影子
----
使用、安裝 pandas

----
### 二、資料科學的實作流程與方法
重點:
* 透視資料與資料清理
* 資料視覺化與特徵擷取
基本上透過 python + pandas 我們可以做到以下這些:
* **讀取資料** - 資料類型與資料結構
* **檢視資料集** - 資料裡面隱藏訊息?
* **資料變身** - 數據形態轉換
* **自由取用想要資料** - 只看符合某種條件的資料
* **資料重塑** - 散落各方的資料大匯集
* **資料清理** - 有問題的做處理
* **數值運算** - 萃取特徵
* **圖解資料** - 一圖抵千言
這部分有興趣的人可以再去學,基本上就是學使用一個語言一個工具,知道大概之後直接實戰最快了!
----
**Q:資料經過處理、分析之後要幹嘛呢?**
很多時候我們會希望透過機器學習去預測、判斷一些趨勢..或者做很多後續的事情,那麼機器學習的了解對於要使用的人來說是很必要的。這塊太大了,有興趣自己去學、去研究,這邊我等等用範例快速帶過。
----
### 三、資料專題實做
當學會上述之後,直接抓題目過來練,也就是:
* 真正執行一個資料科學的分析案例
這邊介紹一個平台 [Kaggle](https://www.kaggle.com/),綜合了上述的資料處理、分析、機器學習,是一個解問題的平台,厲害的人可以在上面解問題拿獎金,就算不厲害在這上面練出一些成績以後入職場也蠻好加分的。
我做了三個練習,其中一個 [titanic](https://www.kaggle.com/c/titanic) 算是入門kaggle的初學者題,類似hello world的存在,第一次都拿這個練手,因為題目久遠且大多數人都寫過,所以網路上很多教學,每個人的寫法都不同,可以研究參考。
接下來直接帶大家參考我的程式碼以及如何使用kaggle
(這個部分請看現場講解)
## 補充
說實在的如果要很充分的學會資料科學並搭配應用,而且目的不是要拿來寫題目,希望可以運用所學到生活、職場中的話,還有很多知識要學,這邊大概列一下必備知識,也是我當初企劃書的一部分,各位如果有興趣可以再個別深入研究
### 知識們
+ Python 基本語法
+ 網頁前端資料取得 熟悉HTML, JavaScript
+ 爬蟲 資料來源 取得 儲存
+ 檔案 csv json xml
+ 開放接口(API)
+ 網頁
+ 靜態網頁爬蟲 `Request`, `Response`, `get`, `post`, `API`, `View`
+ 動態網頁爬蟲 `Selenium + BS4`, `Request + API`
+ 資料儲存與管理
+ 基礎檔案的儲存:CSV / JSON / XML
+ 基於資料庫的儲存:SQL
+ 視覺化與資料探索
+ 機器學習理論
+ 機器學習的種類
+ `監督式學習`, `非監督式學習`, `強化學習`
+ `訓練資料集`, `測試資料集`
+ `模型複雜度`, `資料複雜度`
+ Python 會用到的的套件、工具、概念
+ 爬蟲
+ `網頁解析器:BeautifulSoup`, `url`, `urllib.request`
+ `xmltodict 套件`
+ `小工具安裝: jsonview google extension`
+ `資料定位小工具: 安裝 SelectorGadget google extension`
+ `selenium 套件`
+ `Xpath`,`Phantomjs`,`Ghost`,`Scrapy`
+ 資料分析、資料科學
+ `pandas`
+ `Numpy`
+ `Matplotlib與視覺化`
+ 機器學習理論
+ `Scikit-learn與機器學習`
* 線性迴歸
* 分類-`Logistic`迴歸, `kNN`(k-Nearest Neighbors)
* 分類-`SVM`(Support Vector Machines), `Perceptron`
* 分群-`KMeans`(k-Means Clustering)
### 各個路程的使用工具關鍵字
Request、beatifulsoup、Scrapy =>資料收集
NumPy、 SciPy、 Pandas => 資料前處理
Matplotlib、 Seaborn、 Bokeh、 Plotly => 資料視覺化
Statsmodels、SciKit-Learn、xgboost => 資料模型訓練
TensorFlow(Theano)、Pytorch、Keras => 深度學習
NLTK、Gensim => 自然語言與文本資料處理
### 爬蟲
使用爬蟲做資料蒐集、儲存
大量去各種網站練習爬蟲技巧
熟悉且多樣化的蒐集資料
### 資料處理
使用 NumPy / SciPy / Pandas 做清理、分析、視覺化
將爬蟲爬下來的資料做整理、清理、分類、分析 大量練習
此階段學會後可以先去Kaggle寫入門Titanic的資料處理部分
### 機器學習實作
**I: Regression & Classification**
1.了解迴歸模型與分類問題
* Linear binary classification
* Logistic Regression
* SVM
* Kernel method
2.評估機器學習模型的學習效果
* 損失函數(Loss Function)
* 均方根誤差(RMSE)
* 梯度下降法(Gradient Descent)
* 縮小RMSE
* 模型與參數的選擇
3.判斷模型預測能力的指標
* 混淆矩陣
* 準確率 (Accuracy), 精準度(Precison), 召回率(Recall)
* F-分數 (F-Score)
* ROC曲線
**II: Model evaluation**
1.了解Overfitting
2.避免 Overfitting, Regularization 技巧
3.挑選好的模型, 交叉驗證法(Cross Validation)
**III: 分群 Clustering**
K-means, K-medoids, 最大期望算法,
Hierarchical clustering, DBSCAN, Affinity propagation
**IV: Ensemble learning**
Boosting, Bagging, 決策樹 (Decision tree),
剪枝演算法, 隨機森林 (Random forest)
**V: Feature engineering & Dimensional reduction**
1.特徵工程的應用技術: 遺失值處理, 特徵縮放、轉換、建構、組合、萃取
2.降維演算法與應用: jPCA, kMDS, ltSNE
## 參考資料
+ 競賽練習平台 [Kaggle](https://www.kaggle.com/)
+ 爬蟲
* [Day-1 Python爬蟲小人生](https://ithelp.ithome.com.tw/articles/10202121)
* [Python 爬蟲筆記-1](https://medium.com/@gordonfang_85054/python-%E7%88%AC%E8%9F%B2%E7%AD%86%E8%A8%98-1-15fdec38393c)
* [Python 使用 Beautiful Soup 抓取與解析網頁資料,開發網路爬蟲教學](https://blog.gtwang.org/programming/python-beautiful-soup-module-scrape-web-pages-tutorial/)
+ 資料分析
* [學習計劃|帶你10週入門資料分析](https://medium.com/%E6%95%B8%E6%93%9A%E5%88%86%E6%9E%90%E4%B8%8D%E6%98%AF%E5%80%8B%E4%BA%8B/%E5%AD%B8%E7%BF%92%E8%A8%88%E5%8A%83-%E5%B8%B6%E4%BD%A010%E5%91%A8%E5%85%A5%E9%96%80%E8%B3%87%E6%96%99%E5%88%86%E6%9E%90-66a48503e1b2)
* [Python資料分析(四)Pandas](https://medium.com/@allaboutdataanalysis/python%E8%B3%87%E6%96%99%E5%88%86%E6%9E%90-%E5%9B%9B-pandas-e2fdeb6808c1)
* [python數據分析入門](https://hackmd.io/@cube/Bk9bwQppN)
* [使用 Python 資料分析和視覺化上市櫃公司薪資公開資料](https://blog.techbridge.cc/2019/07/26/how-to-use-taiwan-salary-data-to-do-python-data-analytics-and-data-visualization/)
* [手把手打開Python資料分析大門](https://www.slideshare.net/yenlung/python-84333998)
+ 機器學習
* [附資源與完整指導!帶你從零開始掌握 Python 機器學習](https://buzzorange.com/techorange/2017/08/18/learn-machine-learning-and-python-in-14-steps/)
* ❤️[機器學習:使用Python](https://machine-learning-python.kspax.io/)
* [用 Python 自學資料科學與機器學習入門實戰:Scikit Learn 基礎入門](https://blog.techbridge.cc/2017/11/24/python-data-science-and-machine-learning-scikit-learn-basic-tutorial/)